This post is part of a series where you can follow along as I redesign the blog and my IndieWeb Server.
\nA year ago I began a journey to really rethink how Indieweb functionality could work with a static website.
\nThe hardest part to this process was the architecture, technically I need to be able to create an easy to support system, that is simple to deploy but flexible to allow me to do the interesting things I want to do with data.
\nI think (finally!) the major technical work is coming to an end so I wanted to share my thought process and learnings from what I have done.
\n
Originally I had my static site deploying to Netlify. This was supported by my IndieWeb server running on NodeJs on Heroku which:
\nI would syndicate content by using an XML feed that was periodically polled by Zapier and that would send content to various places.
\nIt all worked but it was incredibly brittle. Problems ranged from:
\nComplexity was also a big driver, I don’t tinker in the code constantly, so even with good naming conventions and logic it can lead to accidentally missing unintended consequences around changing behaviour.
\nI have written in the past around the possibility of combining Lambda functions (or Netlify functions) in to my process. My theory was that on deploying the website, the functions would fire and do things like send a webmention or syndicate content.\nThis was to reduce complexity by moving code from Mastr Cntrl and in to simple “single purpose” functions.
\nI’ll cut to the chase here. I managed to write a working Netlify function that would send webmentions and another that would syndicate content similar to Max Böck’s example here. It wasn’t a fun process at all however. The Netlify Dev CLI was incredibly buggy. I had to re-install Node multiple times, reauthentice and numerous other issues. I burned through hours and hours of free time I couldn’t really spare.
\nThe buggy CLI aside (which I assume will be fixed at some point) I didn’t proceed with this direction for bigger reasons.\nOnce I had the code working I took a step back and realised I had begun to build a dependancy in my build process. When I set out on the path to include Indieweb functionality I always took the approach, that it was the content I wanted to own, not the process.
\nIndieweb approaches may fall out of favour, the web could change radically, the future is unknown. I want to keep the separation of my static site and not intertwine the logic of these processes. It is one of the reasons I offload the creation of Micropub posts to my server and deliver the static file as if I had created it.\nAt a later date I may want to abandon Indieweb and if I ever chose to do so it should be simple and easy to walk away from. Otherwise I am no better than the platforms I am “liberating” my content from.
\nA personal coding thing, perhaps its my experience level, I really didn’t like the way Lambda functions are formed and how they work. It all just felt a bit wrong and this needs to be at least enjoyable to do or I will get bored and go do something else.
\nYou can only run the code for certain conditions. I wanted an “always on” system, which would mean further splitting up my code but not in a logical way. Sending would work, recieving would need to be handled a different way, probably by a separate server or process.
\nI would encourage you to explore Netlify functions for yourself and decide if they (can or would) work for you. They didn’t meet my needs, but they might be exactly what you are looking for. Plenty of people are happy using them!
\nOnce I decided that lambda functions were not right for me, I began to reassess the best way to reduce complexity, eventually deciding upon a Microservices approach.
\nI decided upon separating my concerns in to the following:
\nI could go further and have 2 separate services to send and recieve webmentions etc. My experience with Microservice arhcitecture has been that it pays to break them down and keep them simple within reason. You don’t want to break down services so small that you end up with a distributed system. The aim over a Microservice approach is to try to make it so that each service is not dependant on the other service working and does not possess knowledge of it’s internal working.
\nBy cutting up the responsibilities this way I can have each service work independantly, and where sending content is concerned (syndication and webmentions) I can provide a feed on my static site, that is simply checked periodically triggered by a webhook for content to send.
A further benefit to this approach is that in the future I intend to try and bring in content from my other services such as Scrobbles from LastFm and more. I may add another service to manage this content and insert it in to my website. When I get to adding this the impact against the other services should be zero in both performance and complexity. Life is alot simpler.
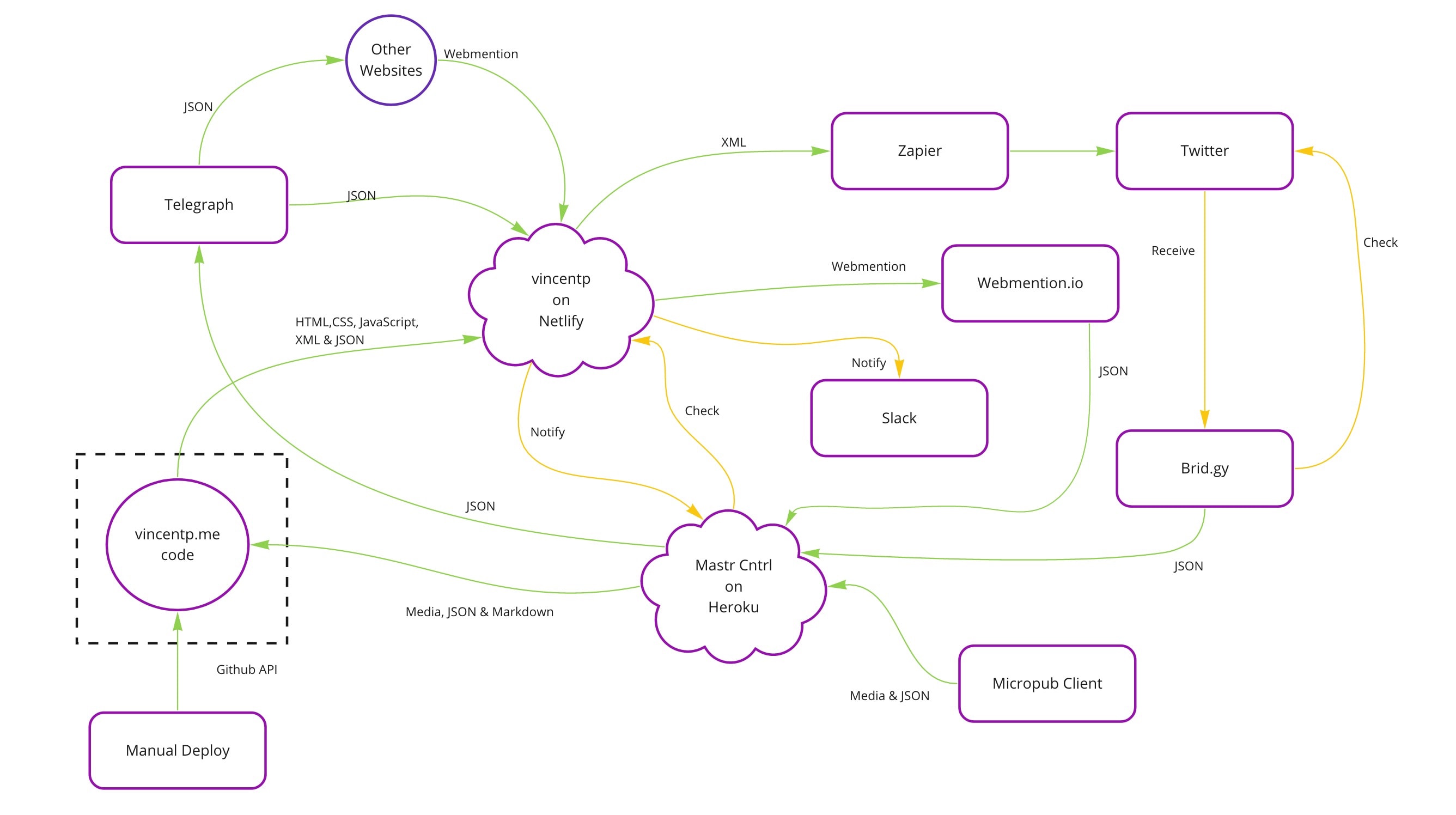
\n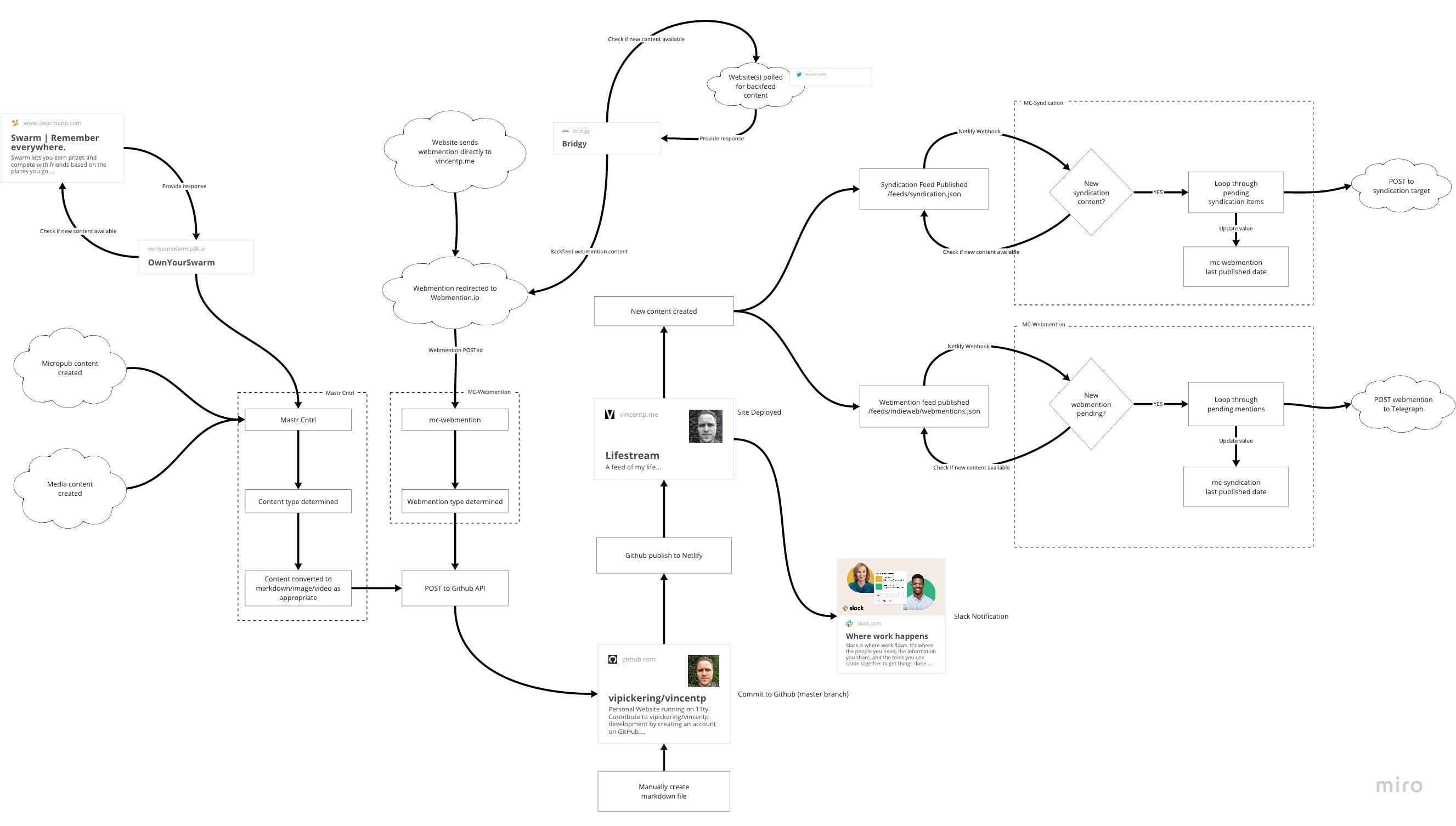
This is my new architecture (you can click on the image for a bigger version).
\nAt first glace it could seem a little overwhelming, but it is simpler than it first appears. Content outlined in dotted lines are the microservices. It is easiest to explain by stepping through a few basic examples.
\nAs you can see in this example Mastr-Cntrl handles the authentication, presents the syndication targets and recieves the content. It formats the content and POST’s it in to my repo. It has no knowledge over syndication whatsoever.
\nMC-Syndication doesn’t have any knowledge of the Micropub part of the process, the whole time it just waits for the webhook to be triggered periodically pings and then checks my JSON feed on vincentp.me, if it “sees” something to do, it takes the JSON feed content and POST’s it to the target and updates it’s last-sent datetime in Github.
If Mastr-Cntrl stopped working, then my syndication service is unaffected. Similiary if there was some issue syndicating (perhaps Twitter denied access). Then my website is unaffected. Additionally, if I decided to stop syndicating in the future, I could just switch the Mc-Syndication service off and nothing else if affected.
\nAs you can probably tell this pattern is very similar to the syndication example above. The MC-Webmention service has no understanding other than to check for a new item in the feed. When it finds one, take the content and POST it.\nFor the webmention service this is much simpler since I use Telegraph to do the sending there is only 1 target.
\nThe process can take a a few minutes to filter through, it works seamlessly and is relatively unchanged from my first implementation in the Monolith. The only difference now is that the Webmention Microservice is responsible instead of a non-related Service.
\nMastr Cnrtl is now a single-use microservice recieving Micropub content, formatting and POSTing to my Github.
\nI have built the Webmention service this is recieving webmentions from Webmention.io. It also sends webmentions from my feed successfully.
\nThe Syndication service is completed with one integration (Twitter). Other servces are in the works such as syndicating bookmarks to Pinboard and it will be easy to extend to other services moving forward. The code is already in place on my website for the feed to except multiple syndication targets.
\nI feel really confident for the first time that I have a strong base to build upon for the redesign work, which should happen quicker and more incrementally than the wholesale architecture work that has taken much longer to get right.
\nThe hardest part is done and I can’t wait to get started on that redesign. I have a wealth of ideas that I am excited to dig in to and share soon.
\n" }, { "author": { "url" : "https://vincentp.me/" }, "title" : "Migrating from Jekyll to Eleventy","summary": "Blog Redesign - Part 4", "date_published" : "2020-03-16T03:00:00Z", "id": 4, "url": "https://vincentp.me/articles/2020/03/16/16-00/", "content_html": "Aplogies this post took so long to get out, I was struck with illness recently and it delayed getting this out. Feeling alot better now 😃
\nThis post is part of a series where you can follow along as I redesign the blog and my IndieWeb Server.
\nNews on the redesign has been quiet for a while as this was (probably) the hardest step in the process. I have a reasonable amount of customised content I wanted to get off the aging Jekyll platform on to Eleventy. I was already customising Jekyll with ruby gems to get my IndieWeb functionality working in a way I was comfortable with, so I took the decision that before I redesign the blog and update the Mastr Cntrl codebase; I wanted a stable platform to build from. In these situations it is very tempting to do the redesign at the same time you re-platform but inevitably this would make the project balloon in to an unacheviable goal for a weekend and evenings project. I needed to keep it acheiveble. One thing I am always concisous of in this project is that potentially there is a contract between actions on Mastr Cntrl and the blog and while (by design) the blog will not stop working if Mastr Cntrl does, I would like to keep everything working if I can and not overcomplicate things.
\nFor the most part you shouldn’t be able to notice the difference. In the move to Eleventy a few things have changed. Most notably I removed the number of webmentions (likes, reposts, replies etc) from a post in my Lifestream. In the redesign I intend to remove these and the work increases complexity and build time so I simply removed them early.
\nIn my day job I preach to “test by doing”. Determine the quickest path to get something working and test it for real, don’t be precious about the method, test first and learn. Then get precious about the quality of the final product once you are clear in the problem(s) you are solving and why you are solving them. Code is a means to an end, you can write the prettiest, most elegant code in the world, but if the system it underpins is complex or hard to comprehend. You code is worthless.
\nI took this approach with my initial pivot to Indieweb and the decision to create my IndieWeb server. The codebase is scrappy and written with a “minimum path to doing”. Over the last 2 years, I have been testing my approach. Thinking around what works and what doesn’t. I learned a lot that is going to inform the next phase. The replatform from Jekyll to Eleventy also took this approach. I recreated the site as close as I could allowing me the space to learn how Eleventy works and feel the edges of what it can do, ask some complicated questions and try to see if it was suitable. If it wasn’t, it was easy to stick with what I had. I didn’t commit to massive evolution of the blog to see it collapse in on itself and get depressed. The worst that could happen was that I had what I already had, the best that could happen, was a path to be better.
\nWhere code is concerned I took the quickest approach to recreate the functionality. Not only did this help in my learning, but I knew I would be throwing away the code afterwards, so its easy to “just do it” and not worry about the quality only the outcomes. It’s a learning exercise to get where I want to be. I am a strong believer that you learn a lot quickly about a process by doing it and making all your mistakes and finding the gotchas. Then you can do it again better.
\nI am sure you have seen many of the blog posts, the tweets, and hype around Eleventy. Posts extolling how they moved their blog over in a few days and it was “super simple”. I am usually sceptical of these things, so before I decided to make the move I did some tests on my codebase and a lot of reading.
\nI have found Eleventy to be a good platform with some really neat ways of doing things and clever tricks, but I would be more measured in my enthusiasm than perhaps others. It is still in its infancy, if you have a complex question information is hard to find without tweeting the author or asking in Github issues, it’s nearly always possible to solve a question asked, but be aware if you are scared of code or don’t want to spend a while learning JavaScript it might be worth doing your own investigation before jumping in. While we are on this topic I should also mention the documentation, its a good start, but I really found both the website and its documentation quite confusing. Finding things is a little tricky until you are really familiar with the navigation on the site (it all looks quite similar, frequently I would be completely lost on the geography of the site) and most of the docs are in the format of introduction followed by a code dump example. It’s just kind-of assumed you know JavaScript well enough to follow the example and understand all the possible contexts you could use it. I was fine with this as I can muddle though, but you might not be. Read the docs before you dive in and decide if you can follow the examples and it makes sense enough. Especially if you are planning to do something slightly out of the normal.
\nOn the plus side the author and the people in the eco-system are friendly and helpful which is a huge benefit and indicates Eleventy will be around for a good stretch. Personally I am quite excited for the platform, it feels a good fit for me and I am looking forward to where it goes.
\nOne of the things I really like about Eleventy and Nunjucks are the way they encourage you to move logic and processing in to the backend and out of your templates. Being able to create Nunjucks custom fillters and Eleventy collections are a neat and efficient way to keep code in the right place and inexpensive. I certainly noticed during this build process that template logic can get expensive fast. Slowing down the build time as the logic is parsed everytime the template is rendered. If you put that complex logic in a tempalte that gets parsed hundreds of times (like a post) its going to get slow quick. Moving the logic in a shared space and letting JavaScript do what it is best is pretty refreshing for a static site generator, often complexity in layouts is left almost entirely in the realm of the templating engine which isn’t a smart choice. This approach lends itself really well to an IndieWeb site that is using webmention data and not loading all the logic in the templating engine. Which leads me to…
\nThe point when I decided Jekyll was no longer meeting my needs came when build times were exceeding one minute. I knew exactly why this was, the logic required to parse through webmentions and output nice HTML code in liquid really put a strain on the engine. Commenting out the templates using webmentions would bring down the build time down from one minute to around ten seconds. It was a big pain, i tried various Ruby Gem solutions but nothing really worked well so I decided I had hit the limit of this platform.
\nDuring the migration to Eleventy I realised a little of this build time penalty was all my own making. Originally I had done what I thought to “keep things simple”. I created a folder in _data called webmentions and saved all the webmentions by the wm-id that comes from webmention.io. But this decision was a big mistake, it meant everytime I wanted to search for all replies to a post I would have to loop through all the data to find the matches. If I then wanted to find the likes, reposts etc I would loop through it again for each type. This would mean I would search and parse the webmentions on average 4-5 times per post, and everyime I added a new post it would magnify the problem further…Oops!
When I ported the code across from Jekyll to Eleventy I left it initially in Liquid and ran the code to see the build time. Eleventy clocked in at 41 seconds average. Between 10 - 15 seconds quicker than Jekyll for the same complex code. Good but I was sure I could do better.
\nThe first step to reducing the time significantly was to separate the types of webmentions before appyling the logic. If I only had 3 reposts in total on the site, but I have hundreds of replies. I really don’t need to loop through the replies at all and certainly not for every post that doesn’t have any. I only care about the data that matters. In practice this was as simple as tweaking the folder structure to be _data/webmentions/replies or _data/webmentions/likes etc. Then creating a collection for each. I did this by globbing the folder, for the sake of getting this migration done. However you can reduce this time further, which I will implement during the redesign.
I back-ported the logic to my Jekyll site while it was live for a direct comparison (and to ease transition later).\nJekyll came in at 27 seconds. Pretty great.\nThen I ran the same test in Eleventy and the build time came down to a shocking 5 seconds . I was impressed, but I know I can do better. Hopefully I can post some better results soon.
\nWhy should we care about build time?
\nTechnically, you don’t have to care if you don’t want to, but I find the exercise of building a static site that is running on a slowly growing set of data and it’s impact on build time quite a fascinating mini project that has good information for others in the same boat and answers questions like, is it really a good idea to do IndieWeb things at all with a static site or is it destined to collapse in on itself at some point? There is lots to learn in this space I feel.
\nTo keep on top of this process, I have created a permanent page to record everything - Review the notes so far.
\nThis post is part of a series where you can follow along as I redesign the blog and my IndieWeb Server.
\nMastr Cntrl is my Indie Web server. It is hosted on Github and Heroku and is open source. It provides the extra layers of functionality and triggers to rebuild my Jekyll website when new content is added, received, or sent to external sources. It’s the biggest and most complicated part of my architecture so this article is a bit more complex than previous posts.
\nUpon deciding an approach to building IndieWeb functionality there was one thing I wanted to ensure. If I break my IndieWeb server, I don’t want the blog to go down.
\nMy blog is a static website and should function as such, layering the additional functionality over the blog and not depending or expecting it to be there. If I remove the IndieWeb server at a later date the content should remain unaffected. I want to own my data and not become a slave to it. Furthermore tying my data to any service, even of my own creation is something to be avoided at all costs.
\nHere is what I scribbled in my notebook a year ago.
\nI managed 3 out of 4. Mastr Cntrl functions are not hot swappable. If I pull a piece of code or functionality there is a high chance it will crash the server. This was a conscious decision when I began building my prototype to try things out and see what sticks. Now my prototype testing is coming to an end it is time to address this.
\nThere is much to cover so I am going to split this up in to logical sections to try and make sure I cover all the angles.
\nI started by attempting to sketch the overall architecture, which took some time, but I eventually arrived at this.
\n
This is an accurate reflection of what I have built so far. It doesn’t look that bad. But there is plenty of opportunity to improve.
\nI like that I have a single point of entry from Mastr Cntrl to the code source (unless I manually write an article or code). I like that it also has a single point out to Netlify. This keeps tight control over my publishing of content and minimises the complexity in getting content on to the site and publishing it out.
\nWhat I don’t like is that Mastr Cntrl is a bit of a black box monolith. “Things” go in and “Something” comes out. That feels like there is a good case to break it down in to separate smaller functions or applications.
\nI have been mulling over the last 6 months if it would be better to translate most or all of Mastr Cntrl’s functionality in to Netlify/Lambda functions. Looking at the architecture, I think I need to explore this option. I prefer smaller moving parts that have a fixed input and output. I am not a software developer so I favour small, simple modules similar to a MicroServices approach. It would be my hope that by doing this I could reduce the amount of reoccurring issues I keep fixing and simplify my technical overheads. I spotted Max Bock wrote about syndicating using Netlify functions a while back, so I need to read through this again and understand what he did and what I can learn from this.
\nI wanted to dig in to what is happening in Mastr Cntrl and get an unbiased view of what data I am receiving and translating. I thought about all the Use Cases. The goal here is to map all the inputs and outputs alongside the context. If I am going to design a better blog, first I need to get a view of:
\n| Input Source | \nInput Type | \nInput Format | \nOutput Type | \nOutput Format | \nOutput Destination | \nIntended Audience | \nPurpose | \nImportance | \n
|---|---|---|---|---|---|---|---|---|
| Telegraph | \nWebmention | \nJSON | \nWebmention | \nJSON | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| Brid.gy | \nWebmention | \nJSON | \nWebmention | \nJSON | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| OwnYourSwarm | \nMicropub | \nJSON | \nCheckin | \nMarkdown | \nWebsite | \nMe | \nRecord Life | \n3 | \n
| OwnYourSwarm | \nWebmention | \nJSON | \nWebmention | \nJSON | \nWebsite | \nMe | \nRecord Life | \n3 | \n
| OwnYourSwarm | \nImage | \nJPG | \nImage | \nJPG | \nWebsite | \nMe | \nRecord Life | \n3 | \n
| Quill | \nMicropub | \nJSON | \nNote | \nMarkdown | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| Quill | \nMicropub | \nJSON | \nBookmark | \nMarkdown | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| Quill | \nMicropub | \nJSON | \nRSVP | \nMarkdown | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| Quill | \nMicropub | \nJSON | \nLike | \nMarkdown | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| Quill | \nImage | \nJSON | \nImage | \nJPG | \nWebsite | \nAll | \nShare With Community | \n2 | \n
| Quill | \nMicropub | \nJSON | \nSyndication | \nXML | \nZapier | \nAll | \nShare With Community | \n2 | \n
| Quill | \nMicropub | \nJSON | \nWebmention | \nJSON | \nTelegraph | \nAll | \nShare With Community | \n2 | \n
| Direct | \nPost Creation | \nMarkdown | \nPost | \nHTML | \nWebsite | \nAll | \nShare With Community | \n1 | \n
| Direct | \nPost Creation | \nMarkdown | \nWebmention | \nJSON | \nTelegraph | \nAll | \nShare With Community | \n1 | \n
| Direct | \nPost Creation | \nMarkdown | \nSyndication | \nXML | \nZapier | \nAll | \nShare With Community | \n1 | \n
| LastFM | \nFeed | \nXML | \nPost | \nHTML | \nWebsite | \nMe | \nRecord Life | \n3 | \n
| Wacht | \nFeed | \nJSON | \nPost | \nHTML | \nWebsite | \nMe | \nRecord Life | \n3 | \n
| Untappd | \nFeed | \nJSON | \nPost | \nHTML | \nWebsite | \nMe | \nRecord Life | \n3 | \n
| Mapbox | \nImage | \nJPG | \nImage | \nJPG | \nWebsite | \nMe | \nRecord Life | \n3 | \n
Creating this table helped me to understand what I was doing and the flow on effects I was producing, with the added bonus of verifying my thinking in the above diagram. To help make this clearer I added an Intended Audience row with the view to understand where content should be when I create it. Presently I dump everything in the timeline which isn’t the most elegant user experience.
\nWhen I thought through the processes, I began to consider the current issues with the website such as Check-ins dominating the timeline. I thought if I consider what I am doing for me and what is for everyone then when I come to looking at the design later, this list will be really handy to identify all my state types and refresh my thinking over its context. To extrapolate that thought further, I added another row that stated my intent over why I am capturing this information. Again this is me thinking ahead to the design stage for a moment and adding context to what is happening here and why. I am sure it will be useful later.
\nWhile I consider the architecture it is worth noting that at currently my content lives across 3 eco-systems. I have no idea on the geography over where this lives except most probably “America”, and I live in New Zealand.
\nApart from the problems in maintaining 3 eco-systems there are also running costs associated. The costs are pretty minimal in all honesty but it is a point nonetheless.
\nIt is worth taking a moment here to also cover reoccurring issues that need specific attention.
\nThe quality of the code is variable, I coded quickly to get up and running so I could understand how and what the IndieWeb was and if I wanted to be a part of it. Now I am comfortable in this space it is the time to rewrite to a higher standard, including some testing!
\nSeb turned 5 last week, so I took a break last week from weeknotes for family time.
\nCat made Seb a giant 5 racetrack cake which went down very well!
\n \n
\nFor Seb’s birthday we took him Go-Karting and 10-pin bowling. Go Karting was a lot of fun Seb managed about 5-10 minutes on his own before he decided to hop in the two-seater with his mum. Not bad for his first effort!
\nUnfortunately when it came to the bowling I have to hang my head in shame, Seb managed to get a strike and a bunch of spares near the end and won!
\nAfterwards we went to Giuseppes in Lower Hutt for some amazing Italian pizzas and gelato.
\nGreat day!
\nWork is slowly progressing on the redesign. My day job is consuming a lot of my time at the moment and the next post in the series is pretty weighty. In a week or so, I should have the time to get back on to it and get things moving.
\n" }, { "author": { "url" : "https://vincentp.me/" }, "title" : "Reviewing my Jekyll set-up","summary": "Blog Redesign - Part 2", "date_published" : "2019-06-30T10:00:00Z", "id": 1, "url": "https://vincentp.me/articles/2019/06/30/22-00/", "content_html": "To keep on top of this process, I have created a permanent page to record everything - Review the notes so far.
\nThis post is part of a series where you can follow along as I redesign the blog and my IndieWeb Server.
\nIn the earlier post I reassessed what I wanted to do with this blog. I re-evaluated and revisited my intentions and set up what I was aiming for.
\nNow it is time to take stock of what I have built.
\nIt is fair to say that I built on impulse to scratch itches on functionality that I wanted to use, but there was not a grand plan. The more I work on Mastr Cntrl the more I trip over the same errors repeatedly or run in to problems I never got around to solving. I forget why I made important decisions and spend hours retracing my steps to understand my decision path.
\nI want to look again at my current architecture through the lens of what was decided in the previous post.
\nLet’s start with the easiest part of the architecture, the static website.
\nThis website is built on Jekyll. I favour a static site generator for blogging, but Jekyll itself was always a compromise. I am not a fan of Ruby and it was the best (at the time) for building a static site generator, but it is slow by modern standards and inflexible.
\nIdeally, I would like to use something built on JavaScript, so I am not switching between languages on the Website and when I work on Mastr Cntrl. Eleventy seems like the smart option to move towards. It supports posts in markdown, so I will not have to do a heavy post conversion exercise (that sounds like hell). I need to investigate this further and make sure I can keep my link structures and other data, so nothing is lost in the move. For the time being, I will assume Eleventy can meet my needs and set some time aside to build a proof of concept. I do not have thousands of posts, but similarly it is still a big job to shift platforms and keep historic content. It would be prudent to investigate this first.
\nI do some slight bending of the Jekyll structure to accommodate Webmentions by storing them in JSON and treating them as data. This is done so I can keep each Webmention separate and keep each Webmention Git history. Which will be helpful later when it comes to supporting removing and updating Webmentions. I do some “fun jumps” in the template to ensure I match the right Webmentions to the right posts. This excessive logic is needed to get around Jekyll’s inflexibility and increases the build time. I would look for an Eleventy solution that does not need this messy code.
\nTo manage content being syndicated out to other providers, such as Twitter. I generate some custom XML feeds at build time and point Zapier at them, unfortunately I didn’t have much success getting Zapier to read JSON feeds which is what I use for everything else. I could get smart and plug Mastr Cntrl straight in to Twitter but I can’t see how the pain would be worth the effort, so for now I will assume this functionality will remain. I will review it when I look holistically at the whole system architecture. It would be nice to get rid of the extraneous XML if I could.
\nSyndicating to IndieNews requires a manual overhead for me to submit the article. I would like to automate this.
\nI need to take a look at the RSS feeds and the data they output. Situations like this seem avoidable:
\n \n
\nI think we can do without a massive face on each RSS post.
\nI pull in map images from Mapbox to generate checkin locations. They look nice, but there is a performance penalty as the page goes to get the images when it is loaded. I would like to see if I can minimise this.
\nCreating avatars from replies and conversation on blog posts is also a page load hog. I don’t have a high traffic blog but even I can notice it once a few replies appear. So I need to investigate better ways of caching or progressively loading this content. Especially since it is only of interest if you want to read or interact with it. But hiding it away could also reduce engagement so I need to think carefully about this one.
\nI host the static website on Netlify (which is awesome). I am going to set some time aside to review my integration with Netlify and in particular using the new Dev functionality in a separate blog post.
\nThere are a number of further integrations I haven’t completed that need to get added to the jobs list. Primarily music and media integration. Music in particular is a huge part of my life which is completly lost on the blog and I want to bring this in more through the redesign.
\nThese points aside I am happy with the current technical way the static site works. The UI & UX on the other hand is not right at all. I mentioned in my previous post that certain content is getting hidden and other content dominating which was not the original intent. I am going to set some time aside to review the design and user experience as a separate exercise in a future post once I’ve finished all my prep work.
\n